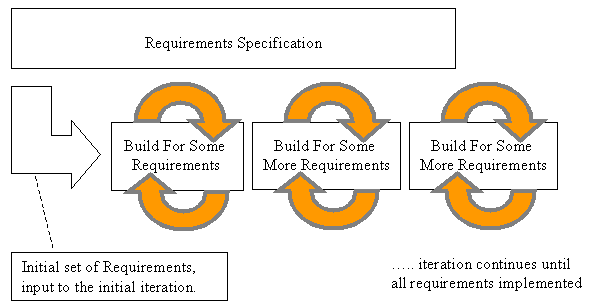
Oracle 8i introduced a feature called VPD (Virtual Private Database); also known as Fine Grained Access Control that provides powerful row-level security capabilities.
VPD works by modifying the SQL commands to present a partial view of data to the users based on a set of predefined criteria. During runtime, WHERE clauses are appended to all the queries to filter only those rows user is supposed to see.
Important: implementing row level security using VPD requires each user to have an actual corresponding user object in database, not just a record in a table. If that's not feasible, then part 3 might be the way to go.
Here is the list of what we need to implement this:
- An Application Context.
- A procedure that sets a variable in the above mentioned context and is called when user login to the database.
- A secured procedure that makes the WHERE clause using the variable that has been set in the context.
- A RLS POLICY that put all these together to tell database how to filter queries.
Let’s assume the tables look something like the following picture (the relationship could be actually many-to-many, but I simplified it).
 Every time a doctor logs in to the system, a procedure is invoked which then sets the value of a variable in Application Context called, say, "logged_in_doc_id" to doctor's doc_id field queried from the Doctors table.
Every time a doctor logs in to the system, a procedure is invoked which then sets the value of a variable in Application Context called, say, "logged_in_doc_id" to doctor's doc_id field queried from the Doctors table.When a doctor queries the list of patients, another procedure filters the data. In this case, we simply add a WHERE clause to the query. Something like this: WHERE f_doc_id = logged_in_doc_id. This WHERE clause will be concatenated to the SELECT command and make it look like this (assuming his id in database is 1): SELECT * FROM PATIENTS WHERE f_doc_id = 1.
Here is the code:
1 & 2 –
As it can be seen, I’ve named the Application Context "NMSPC" and I’ve set the "logged_in_doc_id" variable to the value of "doc_id" field of the record that its "doc_name" field matches with the current logged in user’s name (USER).
CREATE OR REPLACE PACKAGE CONTEXT_SETUP AS
PROCEDURE SET_SESSION_VAR;
END;
CREATE OR REPLACE PACKAGE BODY CONTEXT_SETUP AS
PROCEDURE SET_SESSION_VAR IS
t_id NUMBER(5);
BEGIN
SELECT doc_id INTO t_id
FROM DOCTORS
WHERE UPPER(doc_name) = UPPER(USER);
DBMS_SESSION.SET_CONTEXT
('NMSPC', 'logged_in_doc_id', t_id);
END;
END;
CREATE CONTEXT NMSPC USING CONTEXT_SETUP;
CREATE OR REPLACE TRIGGER EXEC_CONTEXT_SETUP
AFTER LOGON ON JIM.SCHEMABEGIN
CONTEXT_SETUP.SET_SESSION_VAR();
END;
EXEC_CONTEXT_SETUP trigger is called whenever a user (in this instance "Jim") logs in.3 – We need a procedure that creates the predicate; the WHERE clause:
CREATE OR REPLCAE PACKAGE CONTEXT_WHERE_MAKER AS
FUNCTION WHERE_MAKER(obj_schema VARCHAR2,
obj_name VARCHAR2)
RETURN VARCHAR2;
END;
CREATE OR REPLCAE PACKAGE BODY CONTEXT_WHERE_MAKER AS
FUNCTION WHERE_MAKER(obj_schema VARCHAR2,
obj_name VARCHAR2)
RETURN VARCHAR2 IS
BEGIN
IF UPPER(obj_name) = 'PATIENTS'
BEGIN
RETURN 'f_doc_id = SYS_CONTEXT("NMSPC",
"logged_in_doc_id")';
END;
END;
END;
SYS_CONTEXT is a function that helps us to retrieve the value of a variable in a particular context.4 – The last thing we are going to create is a RLS POLICY that put all these together to make them meaningful.
BEGIN
DBMS_RLS.ADD_POLICY
('ALL_TABLES', 'Patients',
'pat_policy',
'JIM', 'CONTEXT_WHERE_MAKER.WHERE_MAKER',
'SELECT');
End;
Please note that "ALL_TABLES" is our schema under which all tables are created and all users have access to.