Well, it may sounds easy and obvious. That’s what I thought when I heard it for the first time. But usually when I ask this simple question that what Iterative Developments is, I get a vague answer. Thus, I decided to write about it.
I use to think the most important part of development is to get the requirements and understand them intelligibly to start development. Well, understanding requirements is very important. But not to collect and understand all detail requirements at the beginning and to start development all the way to the end and maybe showing a prototype to the end user in one stage. Does this sound familiar to you? Well, that’s not what a proper Iterative Development is.
Yes, you have to have an overall and good enough knowledge of the stakeholders’ requirements at the first day, a vision. But detailing requirements and developing them in stages - that are called Iterations - and also informing stakeholders and getting their confirmation for what you have done at the end of each stage are what Iterative Development is composed of.
Maybe the following picture conveys what does that mean:
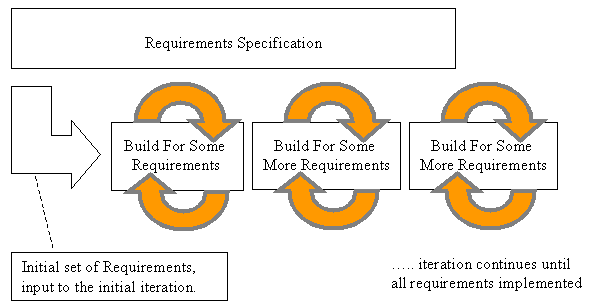 As you can see, this picture shows at each stage some of the requirements are detailed and developed and build. What it doesn’t show is the customer involvement in this process that can be seen in the next picture.
As you can see, this picture shows at each stage some of the requirements are detailed and developed and build. What it doesn’t show is the customer involvement in this process that can be seen in the next picture.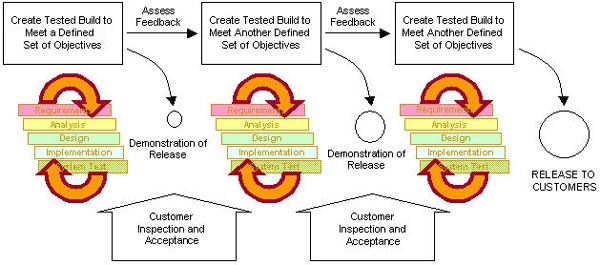 At the end of each iteration you will have a tested build that is representable to the customer and so you will be able to show him your progress and get his feedback and assess it. Of course after that ther will a chance that your plans and documents need to be refined. That shows you are progressing. That's the nature of this way of development.Regarding the management, I must say it’s not an easy responsibility to manage an Iterative Development process. Project manager, need to plan for each iteration before it starts and assess the result when it finishes.I think it's time to show you some of the advantages. To me the most important advantage is mitigating risks. Let’s take a closer look at one of the risks that every project may face, change requests.Which one is easier? Receiving a change request (that your customer thinks is quite small and easy change but in fact it can be devastating) at end of the development process or end of an iteration that you have invited him/her in to see that iteration’s output?Another benefit of iterative approach is having test and test plans early in project. It doesn’t seem right to postpone test to the end of project. You don’t want to see bugs and issues – especially big ones - at the end of development that you believe you are done. Do you?
At the end of each iteration you will have a tested build that is representable to the customer and so you will be able to show him your progress and get his feedback and assess it. Of course after that ther will a chance that your plans and documents need to be refined. That shows you are progressing. That's the nature of this way of development.Regarding the management, I must say it’s not an easy responsibility to manage an Iterative Development process. Project manager, need to plan for each iteration before it starts and assess the result when it finishes.I think it's time to show you some of the advantages. To me the most important advantage is mitigating risks. Let’s take a closer look at one of the risks that every project may face, change requests.Which one is easier? Receiving a change request (that your customer thinks is quite small and easy change but in fact it can be devastating) at end of the development process or end of an iteration that you have invited him/her in to see that iteration’s output?Another benefit of iterative approach is having test and test plans early in project. It doesn’t seem right to postpone test to the end of project. You don’t want to see bugs and issues – especially big ones - at the end of development that you believe you are done. Do you?I hope you got the picture.One more thing, Iterative Development approach is considered troublesome if you don’t have experience or consultant. So please don’t get a real project – even a small one – and try to use this approach if you don’t have someone that has experienced this before. You might end-up with what I did once before.
Let me know if you disagree with me or you have a real case that you want to share with the others.